
目前最官方的资料还是来自OpenAI:OpenAI Sora官方网站
本站做了基于chatgpt4.0的复刻翻译:Sora官方提示文档
一、Sora是什么?
简而言之,通过文本生成视频的大模型
2024年2月16日刚刚发布,直到这篇文章落笔前也不过半个月。
(友情提示:目前openai仍然未开放sora灰度,能使用的是少部分专业用户,对普通人来说,最快接触到sora的方式是先订阅chatgpt plus,官方会首先开放给这批人使用,需要注册升级chatgpt plus的朋友可以看这篇文章,升级chatgpt plus指南,迅速完成升级)
二、Sora的最佳实践在哪里找?
图文翻译:Sora官方提示文档
三、Sora相比原来的短视频生成工具有哪些亮点?
主要有三个:
- 单视频多角度镜头
能一次性生成长达60秒的长视频
- 可读懂世界模型(OpenAI认为,这是实现通用人工智能的重要一步)
具体参考:Sora三大亮点,普通人也能抓住AI风口
四、Sora怎么使用?
4.1 使用sora前的准备工作
在开始前,你需要准备OpenAI的账号,并且拥有Sora的权限,就目前而言,你能做的是先升级到chatgpt plus,占得访问Sora的先机。
4.2 Sora使用步骤一
登陆OpenAI,在指定区域输入你的文本描述,可以是个动作概述,也可以自导自演一部小电影,Sora的能力能够完成一个60s的精致短视频
4.2 Sora使用步骤二
Sora在开始生成之后需要花几分钟处理你的prompt,完成后,你将可以预览生成的视频。
五、Sora的技术原理
5.1 Scaling transformers For 视频生成
Sora采用扩散模型(diffusion model),它通过从一个看起来像静态噪音的视频开始,并通过许多步骤消除噪音来逐渐改变它来生成视频。Sora 能一次生成整个视频,或者对生成的视频进行延长。通过让模型一次预览多个帧,确保即使某个对象暂时离开视野,也能保持一致性。

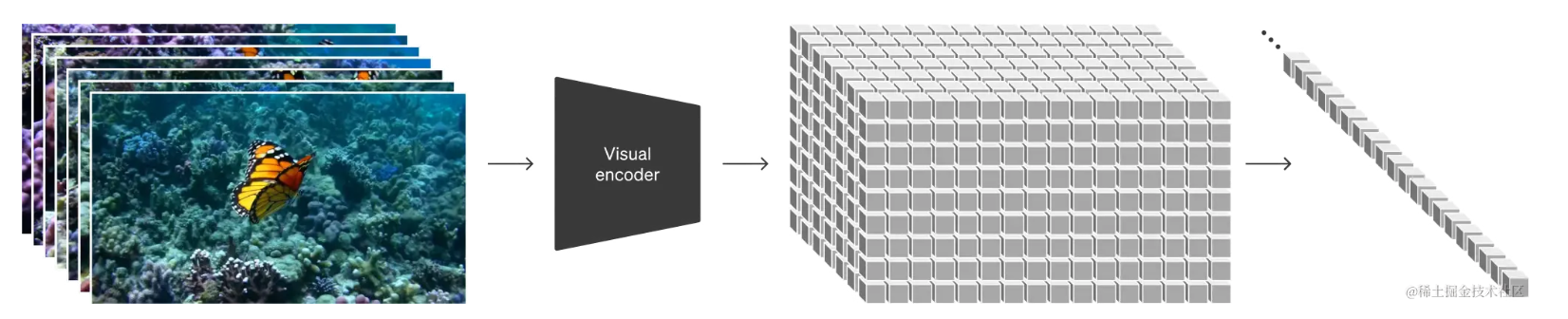
5.2 将视觉数据转化为数据块
将视频和图像表示为被称为数据块(patches)的数据较小的单元集合,每个patches类似于 GPT 中的一个token。通过统一我们对数据的表示方式,我们可以在比以往更广泛的视觉数据范围内训练扩散 Transformer,包括不同的时长、分辨率和纵横比。
六、Sora有哪些局限性呢?
6.1 物理交互模拟局限
OpenAI使用公开可用的视频以及获得授权的版权视频来训练该模型,但没有透露视频的数量或确切来源。在其发布时,OpenAI承认Sora的一些缺点,包括难以模拟复杂的物理学、理解因果关系以及区分左右。
6. 2 安全限制
OpenAI表示,为了遵守公司现有的安全实践,Sora将限制文本提示,以避免生成性、暴力、仇恨或名人形象的图像,以及包含现有知识产权的内容。
6.3 幻觉可能
长序列一致性,由于视频的信息密度比文本大很多,序列建模的复杂度O(LBd),L = sequence length,B = batch_size,d = embedding dimension,视频要在物体描述,风格等细节完全保持一致非常困难,以概率生成方式就可能出现幻觉。
七、展望
Sora的诞生意味着,在文字、图片之后,AI的技术已经突破到了视频领域。虽然在此之前,Runway Gen 2、Pika等AI视频工具已经发布过类似的模型,但相较之下,别家的大模型还在致力于突破几秒内的连贯性,OpenAI已经可以实现60秒的超精细视频制作,这一技术可以说是史诗级别的突破。同时,出色的视频制作能力瞬间“点燃”科技圈。英伟达人工智能研究院首席研究科学家Jim Fan直言,这是视频生成领域的GPT-3时刻。360集团创始人、董事长周鸿祎则称,随着Sora的到来,人类离AGI真的就不远了,不是10年、20年的问题,可能一两年很快就可以实现。
文档信息
- 本文作者:Ken
- 本文链接:https://chatgptzixun.com/2024/03/01/sora-guide/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)